耦合的本质
耦合(coupling)的定义
耦合是对coupling的中文翻译。而coupling是couple的变形,指a connection (like a clamp or vise) between two things so they move together。我相信这就是coupling最朴实的定义。请允许我将其翻译成中文:存在一种连接在两事物之间,以至于这两事物相互影响。
在本文中,耦合可以是一个名词——耦合度的同义词,也可以作为形容词——耦合性的同义词。

软件行业中,耦合从何而来?
至于中文书籍什么时候将coupling翻译成耦合,已经不那么重要了。因为耦合不是从“翻译”而来的。从coupling的定义出发,我们看出不论在哪个层次,不存在绝对不耦合的软件。
软件与业务是需要耦合的,如果不耦合,软件就失去了意义。库存系统是需要和电子商务前端(销售)系统耦合的,否则前端就无法确定是否能供货给用户。如果我们的应用需要使用commons-lang库的StringUtils类,那么我们的应用就要commons-lang耦合的,否则我们没法使用StringUtils中的方法。在函数式编程中,我们的确可以将所有的逻辑(不论技术逻辑还是业务逻辑)封装在没有副作用的一个个函数中,但是我相信这些函数之间还是需要在某个时间点进行耦合。
进而我认为:耦合是“天生”的。
那是不是说我们就可以随意耦合了?显然不是,上述的耦合的例子只是表明耦合的存在性,并没有说明耦合的程度在软件开发过程所起的作用。
所以,和复杂性[1]一样,从根本上来说,我们可以掌握这种耦合,但不能消除这种耦合。
不同级别的耦合
软件是由不同级别的概念层组成,不同级别的概念层具有不同的职责,不同级别的概念层中存在不同的耦合:有方法级别、类级别、包级别、协议级别、语言级别、数据流级别、数据库级别、业务级别……
方法级别:这不用多说了。
类级别:如果你了解“组合优于继承”原则,你就应该理解什么叫类级别的耦合。这里并不是说继承不好,而面对不同的问题,你需要权衡是“组合”还是“继承”与问题模型更匹配。
语言级别:我们的业务必须使用某各种语言来表达,无论是DSL还是通用编程语言Java、C#。
数据流级别:数据流是指一种我们处理问题的方式:输入数据,然后数据在一条充满处理环节的链上流动,直到完全最后一个处理环节输出处理结果。这很像我们的面向切面编程。
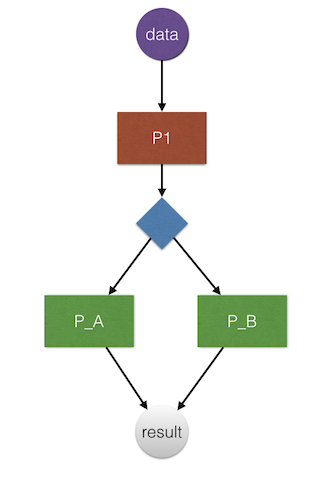
如果P_A要求输入的数据中的日期格式是: YYYY-MM。某天一个新手不小心把在P1中把日期格式改了,那么P_A就会出错。而现实中,我就遇到过一个数据处理流中有将近20多个处理环节,目前几乎没人敢动那块逻辑。另一个例子就是项目使用了Spring的切面编程,由于“切”得太多,到后来调试起来,我不得不遍历所有的切面的逻辑,以确定数据流到哪个环节出的错。
数据库级别:如果你的应用使用到了数据库Oracle特有的特性,那么你的应用就是和Oracle数据库耦合的。想像一下阿里去O的过程。也可以看下这篇文章:http://tech.it168.com/a2015/0417/1720/000001720950.shtml。ORM框架的好处在这方面尤为突出。
通信协议级别:如果通信的双方只依靠协议通信,而不关心实现这个协议的是Ruby程序还是Java程序。这也正是基于HTTP的 RESTFul风格的架构的关键所在。而业界提的微服务思路,其实就是期望各个应用之间只在协议级别耦合,从而与语言、操作系统解耦。通信协议级别上,我们也需要考虑解耦,比如,你的应用能否轻松从HTTP协议迁移到HTTPS。
操作系统级别:文件的路径的写法在各个系统下的不同,所以Java才会有: File.separator 这个常量,在Windows环境下返回\,而在*nix环境下返回/。如果不用此常量来拼文件路径,那么,那部分就是与操作系统耦合的。像:
for Windows: C:\windows\system32\cmd.exe
for Linux: /var/log/ansible.log
有些人觉得这不如挂齿,看看这条新闻:坚持用 XP 的代价:美国海军付给微软上千万。
PS:使用Ruby的某些gem时就要小心,因为某些gem用到了操作系统的库。 如Nokogiri (鋸)
业务级别:业务级别上的耦合度越高,软件的风险系数越高。假如A公司的领导在职时采用代码行数来KPI程序员,代码行数越多,KPI越好。如果在为这家公司设计HR系统时,你就必须考虑如果A公司换领导了或者原领导反省了,换采用360度评估进行KPI。你的系统能否以相当小的代价实现?又比如政府的某些老系统将一代身份证的身份证号作为自然人在数据库中的ID。可是某天,二代身份证出了,身份证号变成了18位了。那么如果自然人要求更新系统中的身份证号,你怎么办?
比较好玩的是,有时我们的程序有时会和系统用户耦合。
apache-commons-io 下的设置文件的可读/可写权限时,如果使用的是root用户执行此程序会有问题,因为root可对所有的文件可读。
File tmpFile = File.createTempFile(getClass().getSimpleName(), ”localities.xml”);
tmpFile.deleteOnExit();
tmpFile.setReadable(false);
Assert.assertFalse(tmpFile.canRead()); // It would be failed
这个assert将会失败,因为不论该文件是否可读,以root用户执行此程序时,tmpFile始终是可读的。
了解“不同级别的耦合”有什么用?
在现实中,我们开发软件时需要做很多的权衡。在权衡过程中,对于不同级别的耦合度的思考为我们提供了很好的参考。例如在选择使用什么内容来做数据库人员表的ID时,如果你知道身份证ID可能会变,你绝对不会使用身份证ID作为数据库表ID。但是你可能知道它会变吗?你不知道。所以,最后答案是使用与业务、具体技术没有任何关系的UUID或者数据分配的自增int值。
低耦合代表什么
不少书籍都告诉我们要追求高内聚(High Cohesion)及低耦合(Low Coupling)的软件?但是为什么?我见到答案无非就是:高内聚和低耦合可以给我们软件开发人员带来可读性、复用性、可维护性和易变更性。
但是这里存在一个本质问题:为什么高内聚低耦合能给我们带来这“四性”?以及两个伴生问题:高内聚和低耦合在软件中分别达到什么比例才能达到四性、内聚要高到什么程度和耦合要低什么程度才能达到四性。要回答这个问题,我们首先必须分别给这四个“性”进行定义。
可是什么是可读性,怎么样的代码才算可读?什么才叫得复用?怎么样才算可维护?易重构?易加需求?……诚然弄清楚这些问题比耦合这个topic更重要,但不是本文讨论的范围。
所以,我不打算从别人的结论进行反问以得到答案。我们从另一个角度反问:高耦合给我们带来了什么?不幸的是,我们至今仍然没有权威的统计数据告诉我们高耦合给我们带来了什么。如果你发现,请告诉我。
是的,这里引出我们软件行业中各种概念、理念、方法学的一个通病:没有数据支撑。
但是,我们这样就算了吗?不。我们尝试从耦合原始定义出发,耦合意味两事物相互连接,并相互影响。如果这两事物之间的连接越多,则相互影响的机率就越高,我们认为这就是高耦合。否则就是低耦合。
我们将“两事物”特化为两个软件系统如企业中的财务系统和HR系统,高耦合意味着我们对HR系统的变更,影响到财务系统的机率高。夸张点说就是,我们以为只是对HR系统进行一次小小的修改,但是要对财务系统进行不少修改。再换句话说就是两个系统不能独立演进。低耦合则反之。
低耦合代表的是在软件不同级别的概念上只依赖它需要依赖的,从而达到它本身的修改不至于造成其它系统的非必要影响,反之亦然。
但是又回到老问题:什么叫做“只依赖它需要依赖的”、“非必要影响”?这个问题就像你问你的男/女朋友:你有多爱我?我没有办法准确回答。但是,我会告诉你我是如何思考耦合度的,在我做决策时。也就是我会告诉你,我是怎样爱你的。你觉得那样算不算爱你,答案只有你知道。

耦合的本质是什么?
事实上,在软件开发过程中,我认为耦合的本质是假设。
在设计软件过程,在业务级别上,对与其交互的业务的假设是什么?它需要使用哪些具体技术,可否将这些具体技术隔离出去,以至于我可以低成本的更换实现,也就是减少对具体技术的假设。在写代码时,方法级别上它是不是对其它方法的处理结果进行假设了?类级别的设计有什么假设?等等。
总的来说,就是找到软件开发过程中每个环节可能的假设,并问:如果这个假设并打破了,系统会受到什么影响?
这是一种思考方式。所以,它是普世的。
在团队管理过程中,你可以假设某个人离职了,会产生什么影响?如果这个人很重要(关键人物),那么你就要考虑如何push他去share knowledge了。在公司运营中,假设某项业务占了公司总体的99%,那么就你要考虑什么样的可能性会将这个假设打破?因为打破这个假设,这个公司99%就跨了。如果你知道软件系统的假设,那么在测试过程,你就更知道如何有效测试了——打破这些测试,看发生什么。
总结
耦合是天生的,不存在绝对不耦合。耦合的本质是假设,假设越多,被打破的机率就越高,所以软件的可靠性就越低。低耦合代表的是在软件不同级别的概念上只依赖它需要依赖的,从而达到它本身的修改不至于造成其它系统的非必要影响,反之亦然。
在软件开发过程中,我们应该管理这些耦合,不论在哪个级别上。应该经常考虑如果这些假设被打破了,会给系统带来哪些风险。
但是低耦合并不代表没有成本。ORM框架使我们与具体数据库解耦,但是在性能上,我们可能就有所失。我们必须权衡这些利弊。有没有好的办法帮助我们做权衡呢?可惜。我能看到的全靠这个做决策的人的经验。
[1]《面向对象分析与设计》Grady Booch. P7
部分图片来自网络,如有侵权,请联系我。
End
